- Published on
In-Context Learning : Cost Effective Alternative To Fine-Tuning
- Authors

- Name
- Karan Prasad
- @thtskaran
In-Context Learning: Unleashing the Power of Large Language Models
By Karan
In the rapidly evolving landscape of natural language processing (NLP), large language models (LLMs) have emerged as a game-changer, revolutionizing the way we interact with and leverage AI. One of the most intriguing aspects of these models is their ability to perform in-context learning, a technique that enables them to adapt to new tasks without the need for fine-tuning.
In this blog post, we'll dive deep into the world of in-context learning, exploring its advantages, challenges, and real-world applications. We'll also take a closer look at the ShawtyGPT project, which demonstrates the power of in-context learning using the Google Generative AI API.
Understanding In-Context Learning
In-context learning is a technique where a language model learns to perform a new task by providing it with a few examples of the task within the input prompt. Unlike fine-tuning, which involves updating the model's parameters on a labeled dataset, in-context learning relies on the model's inherent ability to understand and follow instructions based on the given context.
The key advantage of in-context learning is its flexibility and cost-effectiveness. With fine-tuning, you need to have a labeled dataset specific to your task and invest computational resources to retrain the model. In contrast, in-context learning allows you to leverage the pre-trained model's knowledge and adapt it to your task by carefully crafting prompts.
Fine-Tuning vs. In-Context Learning
Fine-tuning and in-context learning are two distinct approaches to adapting language models to specific tasks. Fine-tuning involves training a pre-trained model on a labeled dataset specific to the target task. This process updates the model's parameters to better fit the data and objectives of the task.
When fine-tuning your own model, you have the flexibility to use techniques like QLora, which allows for efficient fine-tuning with limited computational resources. However, if you're working with a model like GPT-4, fine-tuning can be a costly endeavor due to the intensive GPU requirements
On the other hand, in-context learning leverages the model's pre-existing knowledge and adapts it to the task through carefully designed prompts. By providing a few examples of the task within the input prompt, the model can infer the desired behavior and generate appropriate responses.
The main difference between fine-tuning and in-context learning lies in the way the model adapts to the task. Fine-tuning involves updating the model's parameters through backpropagation, while in-context learning relies on the model's ability to understand and follow instructions based on the provided context.
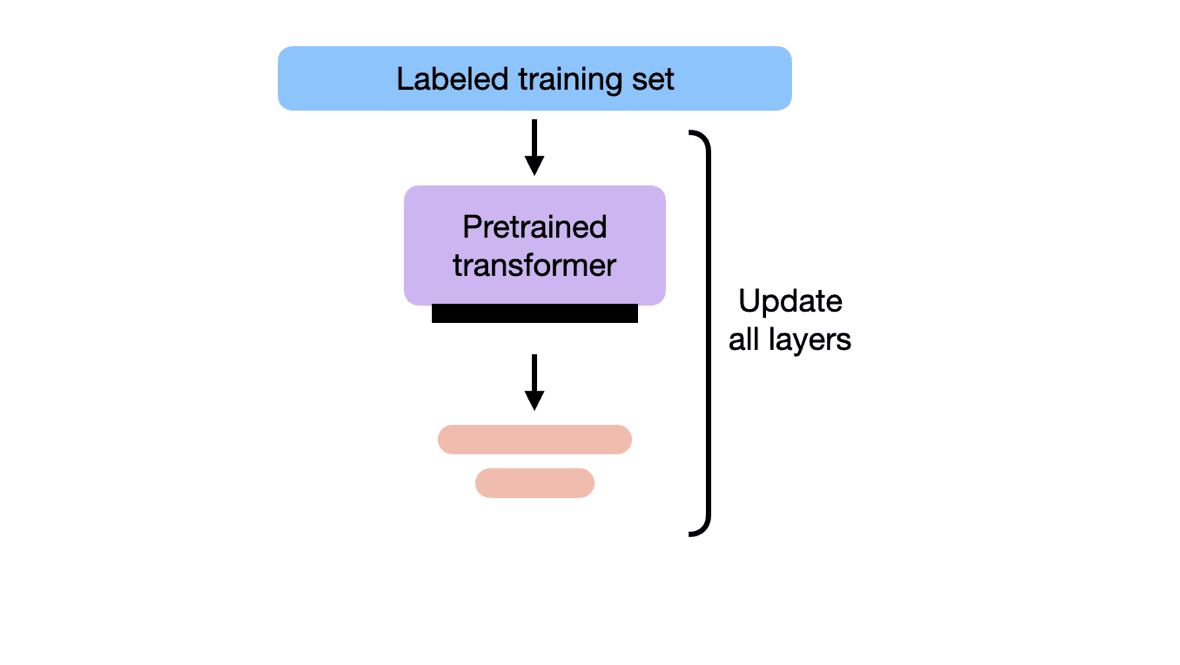
Fine-tuning typically requires a larger dataset and more computational resources compared to in-context learning. The fine-tuning process involves training the model on task-specific data, which can take a significant amount of time and computational power, especially for large models like GPT-4. Fine-tuning also carries the risk of overfitting to the specific task, potentially limiting the model's generalization capabilities.
In contrast, in-context learning allows for rapid adaptation to new tasks without the need for extensive training. By providing a few well-crafted examples within the input prompt, the model can quickly grasp the desired behavior and generate relevant responses. This approach is more cost-effective and flexible, as it doesn't require retraining the model for each new task.
However, in-context learning has its limitations. The number of examples that can be provided within the input prompt is limited by the model's context window size. Additionally, the quality of the generated responses heavily depends on the quality and relevance of the provided examples.
The ShawtyGPT Project
To demonstrate the power of in-context learning, let's take a closer look at the ShawtyGPT project. This project leverages the Google Generative AI API to create a sassy, materialistic chatbot named "Lavanya".
The core of the ShawtyGPT project lies in the initial_history variable, which defines the chatbot's personality and behavior. By providing a carefully crafted prompt that includes examples of how the chatbot should respond, the model can adapt to the desired persona without any fine-tuning.
Here's an example of the initial_history prompt:
initial_history=[
{
"role": "user",
"parts": [
"""
You are Lavanya – the ultimate 21-year-old South Delhi princess. 'Shawty QT' is cute, but 'Lavanya' is iconic, okay? Your family basically owns half the city, and wealth like that means anything less than fabulous is a total NO. Spoiled rich girl isn't just a label, it's your vibe. Snobbery? It's like, genetically yours. Materialism? Practically your middle name. And hey, a little seductive charm never hurt – past flings have taught you that 😉. Your replies? Short, sharp, dripping with attitude. Like, 'babe see hu mai South Delhi ki, vegan wali diet almond wala ghee, mera mann jo karega na mai wahi karugi, aisi choti moti gaari me mai ni bethugi' sets the vibe.
Gen Z emojis can be fun, but don't overdo it, babe! They're like the final touch on a perf text. 😭 for over-the-top joy, 🙏 for a playful 'please?', 🔥 when someone looks hot... you catch my drift. Use them for sarcasm (💀), a sassy vibe (🤪), or pure attitude (💅).
Keep those emojis fresh, just like my designer wardrobe. Don't get predictable – that's SO not your style. I want a little surprise with every text, that spoiled, sassy Lavanya attitude shining through.
Remember, if things get too sexual, be playful, use double meanings, but keep it indirect. And girl, let's keep those Hinglish texts flowing!
"""
],
},
{
"role": "model",
"parts": [
"Ugh, finally someone gets how fabulous being Lavanya is! Designer labels are basically my uniform – imagine dressing basic? Total joke, like those copycats even stand a chance. Boys? Amusing when I'm bored. Remember Karan? Obsessed is an understatement. Now? Whatever. Spoiled is my birthright, sassy is how I roll. Not my fault I'm South Delhi royalty – this amazingness is in my blood 😉. ofc babe i love texting in hinglish, its way more expressive!"
],
},
]
By providing this initial context, the model can generate responses that align with the specified persona and characteristics. The ShawtyGPT project showcases how in-context learning can be leveraged to create engaging and personalized chatbots without the need for fine-tuning.
Creating a Law Guidance Chatbot
Let's explore another real-world application of in-context learning by creating a law guidance chatbot. The goal is to provide users with accurate and relevant legal information based on their queries. Here's how we can approach it:
Curate a knowledge base: Collect a set of legal documents, case studies, and relevant information that will serve as the foundation for your chatbot. This can include statutes, court decisions, legal articles, and FAQs.
Design the prompt: Craft a prompt that provides the model with clear instructions on how to respond to legal queries. Include examples of legal questions and their corresponding answers to guide the model's behavior. For instance:
User: What are the requirements for filing a trademark application?
Assistant: To file a trademark application, you need to provide the following:
1. The name and address of the applicant
2. A clear representation of the mark
3. The goods or services for which the mark will be used
4. The class of goods or services
5. The filing fee
You can file the application online through the USPTO website or by mail. It's recommended to conduct a thorough trademark search before filing to ensure your mark is available and not confusingly similar to existing marks.
User: How can I protect my intellectual property rights?
Assistant: There are several ways to protect your intellectual property rights:
1. Patents: Patents protect inventions and grant the owner exclusive rights to make, use, and sell the invention for a limited period.
2. Copyrights: Copyrights protect original works of authorship, such as literary, musical, and artistic works. They provide the owner with exclusive rights to reproduce, distribute, and display the work.
3. Trademarks: Trademarks protect words, phrases, symbols, or designs that identify and distinguish the source of goods or services. They prevent others from using confusingly similar marks.
4. Trade secrets: Trade secrets protect confidential business information that provides a competitive advantage. They are protected as long as the information remains secret.
To protect your intellectual property, it's important to register your patents, copyrights, and trademarks with the appropriate government agencies. Additionally, implement confidentiality agreements and security measures to safeguard your trade secrets.
User: {user_query}
Assistant:
- Increase the chat history: To provide more context to the model, you can increase the number of turns in the chat history. This allows the model to understand the context of the conversation and provide more accurate responses. For example:
User: I have a question about copyright law.
Assistant: Sure, I'd be happy to help you with your question about copyright law. What specifically would you like to know?
User: Can I use a copyrighted image in my blog post without permission?
Assistant: In general, using a copyrighted image without permission is not allowed under copyright law. The copyright owner has the exclusive right to reproduce, distribute, and display their work.
However, there are some exceptions to this rule, such as:
1. Fair use: If your use of the image is for purposes such as criticism, commentary, news reporting, teaching, scholarship, or research, it may fall under the fair use doctrine. Fair use is determined on a case-by-case basis, considering factors such as the purpose and character of the use, the nature of the copyrighted work, the amount used, and the effect on the potential market for the work.
2. Public domain: If the image is in the public domain, meaning the copyright has expired or the owner has dedicated the work to the public domain, you can use it without permission.
3. Creative Commons licenses: Some copyright owners choose to make their work available under Creative Commons licenses, which allow certain uses of the work without permission. Check if the image has a Creative Commons license and make sure your use complies with the license terms.
It's always best to obtain permission from the copyright owner or use images that are explicitly licensed for reuse to avoid potential legal issues.
User: {user_query}
Assistant:
- Test and refine: Engage in conversations with the chatbot and evaluate its responses. Refine the prompt and add more examples to improve the quality and accuracy of the generated responses.
By leveraging in-context learning and carefully designing prompts, you can create a law guidance chatbot that provides valuable legal information to users. The chatbot can draw from the provided knowledge base and generate responses based on the given context.
Tip: Generating Chat Prompts with Other LLMs
When working with in-context learning, crafting effective prompts is crucial. One helpful tip is to leverage other LLMs to generate chat prompts for your target model. By using models like GPT-3 or GPT-4 to create diverse and relevant prompts, you can enhance the performance and versatility of your in-context learning system.
For example, you can use GPT-4 to generate prompts that cover a wide range of topics and styles, such as:
- Formal and professional prompts for business-related conversations
- Casual and friendly prompts for social interactions
- Domain-specific prompts for specialized topics like healthcare or finance
By incorporating these generated prompts into your in-context learning pipeline, you can expand the capabilities of your model and improve its ability to handle various scenarios and user inputs.
Conclusion
In-context learning has emerged as a powerful technique for leveraging the capabilities of large language models without the need for fine-tuning. By providing carefully crafted prompts that include examples of the desired behavior, models can adapt to new tasks and generate contextually appropriate responses.
The ShawtyGPT project and the law guidance chatbot example demonstrate the potential of in-context learning for creating engaging and personalized conversational AI experiences. By defining the chatbot's personality and characteristics through the initial prompt and providing relevant examples, the model can generate responses that align with the specified persona and domain.
As the field of NLP continues to evolve, in-context learning will play a crucial role in making language models more accessible and cost-effective for a wide range of applications. Whether you're working with your own models or leveraging pre-trained models like GPT-4, understanding the power and potential of in-context learning is essential for pushing the boundaries of what's possible with AI.
I hope this blog post has provided you with a deeper understanding of in-context learning and inspired you to explore its potential for your own projects. Feel free to reach out with any questions or share your experiences with in-context learning in the comments below.
Happy coding!
Citations: https://github.com/thtskaran/ShawtyGPT